Es fácil pensar en sistemas que
están compuestos por tres componentes: UI, reglas de negocio y la base de
datos. Para algunos sistemas más simples es suficiente pero para otros el
número podría ser mayor.
Por ejemplo, si se considera un videojuego es fácil imaginar tres componentes. La
UI que se encarga de transmitir los mensajes desde el jugador a las reglas de
juego. Las reglas de juego almacenan el estado del juego en algún tipo de
estructura de datos persistente. Pero, ¿eso es todo?
HUNT THE WUMPUS
HUNT THE WUMPUS es un juego basado en texto creado en 1972. Este juego utiliza simples
comandos como «Go east» and «shoot west». El jugador introduce un comando y la
computadora responde con lo que el jugador ve, huele, escuchar y experimenta.
El juego consiste en que el jugador está cazando Wumpus en un sistema de
cavernas y debe evitar trampas, pozos y otros peligros.
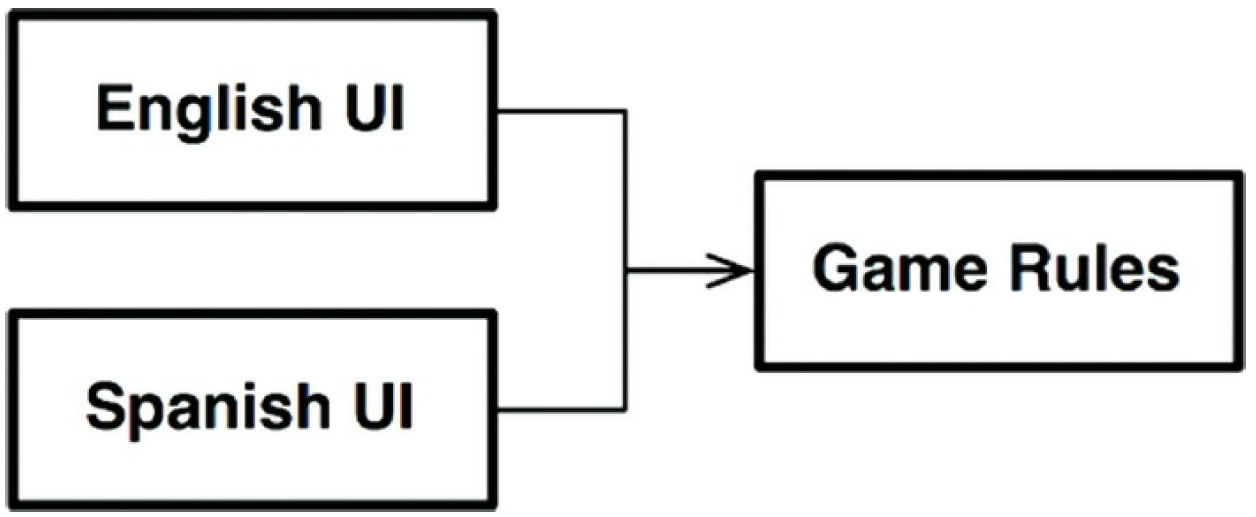
Asumiendo que mantendremos la UI basada en texto pero esta está desacoplada de las reglas
de juego, así que nuestra versión puede usar diferentes lenguajes en diferentes
mercados. Las reglas de juego comunicarán con el componente UI usando una API
independiente del lenguaje y la UI traducirá a la API al lenguaje apropiado.
Si las dependencias de código están administradas correctamente, entonces el número de
componentes de UI pueden reusar las mismas reglas de juego. Las reglas de juego
no sabe o no les importa que el lenguaje de la interfaz.
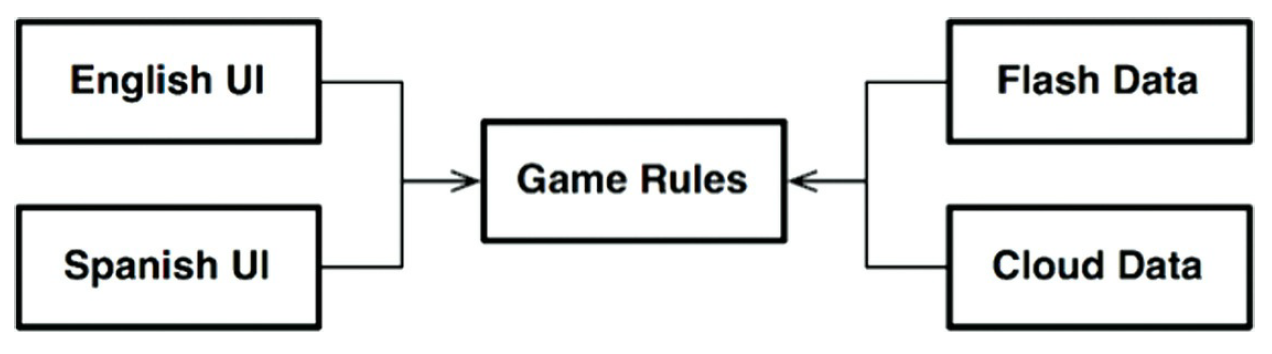
Asumamos que el estado del juego se mantiene en algun almacenamiento persistente el cual
podría ser en una memoria flash, en la nube, o en la RAM. En cualquiera de
estos casos, nosotros no queremos que las reglas de juego conozcan los
detalles. ASí que, se creará una API para que las reglas de juego se puedan
comunicar con el componente de almacenamiento de datos.
Nosotros no queremos que las reglas de juego sepan nada sobre los diferentes tipos de
almacenamiento de datos, así que las dependencias tienen que estar propiamente
dirigidas siguiente las reglas de dependencia como se muestra en la siguiente
figura.
¿Arquitectura limpia?
Debería estar claro que nosotros podríamos aplicar la estrategia de arquitectura limpia
en este contexto con todos los casos de uso, los límites, las entidades y las
estructuras de datos correspondientes. Pero, ¿hemos encontrado realmente todo
el significado de los límites arquitectónicos?
Por ejemplo, el idioma no es sólo el eje de cambio para la UI. También queremos
variar el mecanismo por el cual nosotros comunicamos el texto. Por ejemplo,
nosotros podríamos querer usar una ventana de shell, o mensajes de texto o una
aplicación chat. Hay muchas posibilidades diferentes.
Esto significa que hay un límite potencial arquitectónico definido por este eje de
cambio. Quizá deberiamos construir una api que cruce ese límite y aisle el
idioma del mecanismo de las comunicaciones, esta idea se ilustra en la
siguiente figura.
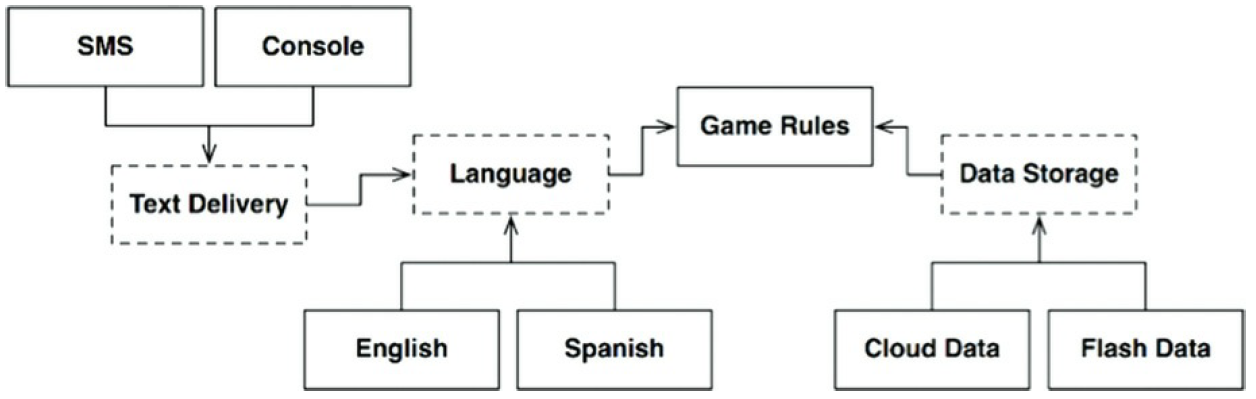
Este diagrama es un poco más complicado pero no debería tener sorpresas. Las líneas
punteadas definen componentes abstractos que definen una API que está
implementada por componentes que están ubicados debajo o encima de estos. Por
ejemplo, la API «Language» tiene la implementación «English» y «Spanish».
«GameRules» se comunica con «Language» a través de una API que «GameRules» define y
«Language» implementa. «Language» comunica con «TextDelivery» usando una API
que «Language» define y «TextDelivery» implementa. La API la define el usuario
de esta más que el implementador.
Si miramos dentro de «GameRules» encontraríamos interfaces de límites polimórficos que se
usan dentro del código de «GameRules» y se implementan por código dentro del
componente «Language». También deberíamos encontrar interfaces de límite
polimórfico usadas por «Language» y que se implementan en el código dentro de
«GameRules».
Si miráramos dentro de «Language», podriamos encontrar la misma cosa: interfaces
de límite polimórfico que se implementan dentro de «TextDelivery» e interfaces
de límite polimórfico que se usan en «TextDelivery» y se implementan en
«Language».
En cada caso, la API definida por aquellos interfaces límite son propiedad del
componente ascendente.
Las variaciones como «English», «SMS» y «CloudData» son provistos por interfaces
polimórficas definidas en el componente API abstracto e implementadas por
componentes concretos. Por ejemplo, esperaríamos interfaces polimórficas
definidas en «Language» para ser implementadas en «English» y «Spanish».
Se puede simplificar este diagrama eliminando todas las variaciones y enfocandose en los
componentes API simplemente.
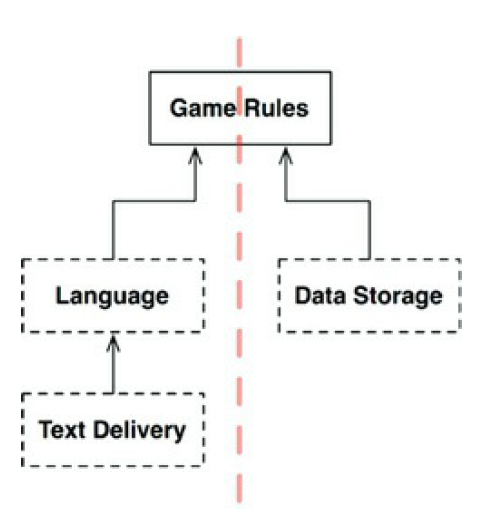
Se puede apreciar que el diagrama tiene una orientación y que todas las flechas
apuntan hacia un componente en su parte superior con el componente «GameRules»
en la parte superior. Esta orientación tiene sentido dado que el componente
«GameRules» es el componente que contiene la política de más alto nivel.
Considerando la dirección del flujo de información se puede observar que toda la entrada
viene desde el usuario a través del componente «TextDelivery» en la parte
inferior izquierda. Esa información se eleva a través del componente
«Language», traduciéndose a comandos para «GameRules». «GameRules» procesa la
entrada de datos de usuario y envía datos apropiados a «DataStorage».
Entonces «GameRules» envía la salida de regreso a «Language», el cual traduce la API de
vuelta al idioma apropiado y entonces entrega ese idioma al usuario a través de
«TextDelivery».
Efectivamente, esta organización divide el flujo de datos en dos partes. El flujo de la
izquierda que está ligado a la comunicación del usuario y el flujo de la
derecha el cual concierne a la persistencia de datos. Ambos flujos se
encuentran en «GameRules», el cuál es el último procesador de datos que va a
través de los dos flujos.
Cruzando los flujos
¿Hay siempre dos flujos de datos como en este ejemplo? No, no en todos. Imagina que
nos gustaría jugar al «Hunt the Wumpus» en la red con múltiples jugadores. En
este caso, necesitaríamos un componente de red, como se muestra en la siguiente
figura.
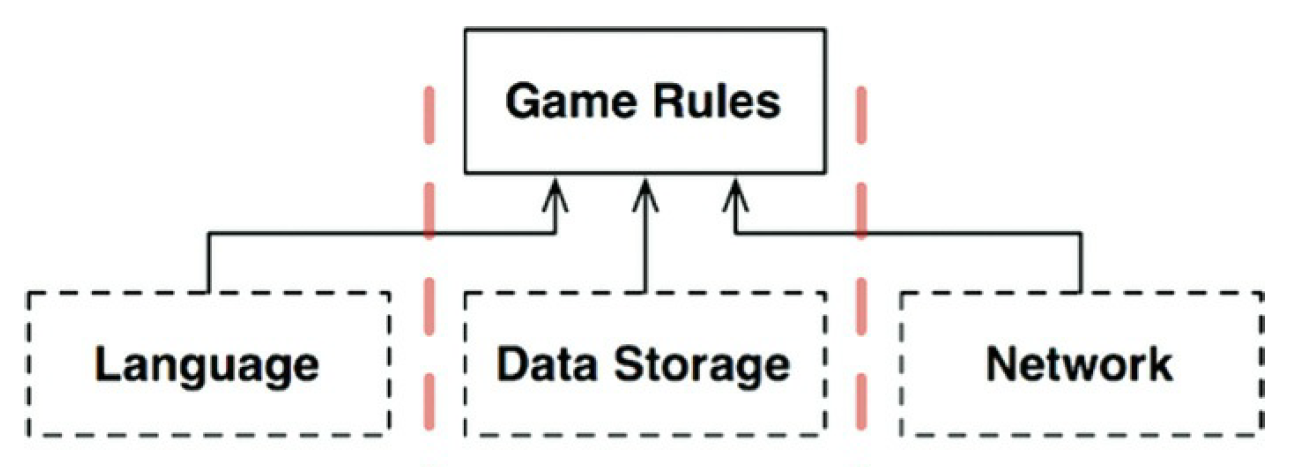
Esta organización divide el flujo de datos en tres flujos. Todos ellos controlados
por «GameRules». De esta manera el flujo se convierte en más complejo, la
estructura de componentes puede dividirse en muchas secuencias.
Dividiendo los flujos
En este punto se podría pensar que todos los flujos se encontraría eventualmente en la
cima en un único componente. ¡Si sólo la vida fuera así de simple! La realidad,
por supuesto, es mucho más compleja.
Considerando el componente «GameRules», parte de las reglas de juego tratan con los
mecanismos del mapa. Estos saben cómo están conectadas las cavernas y qué
objetos están localizados en cada caverna. Saben como mover el jugador de una
caverna a otra y como determinar los eventos con los que el jugador debe tratar.
Pero hay otro conjunto de políticas en un alto nivel, políticas que saben la salud del
jugador, el coste o beneficio de un evento en particular. Estas políticas
podrían causar una pérdida gradual de salud o ganar salud por descubrir comida.
La política de mecanismos de bajo nivel declarará eventos a la política de algo
nivel como «FoundFood» o «FellInPit». La política de alto nivel administraría
el estado del jugador. como se muestra en la siguiente figura. Eventualmente,
esa política decidiría si el jugador gana o pierde.
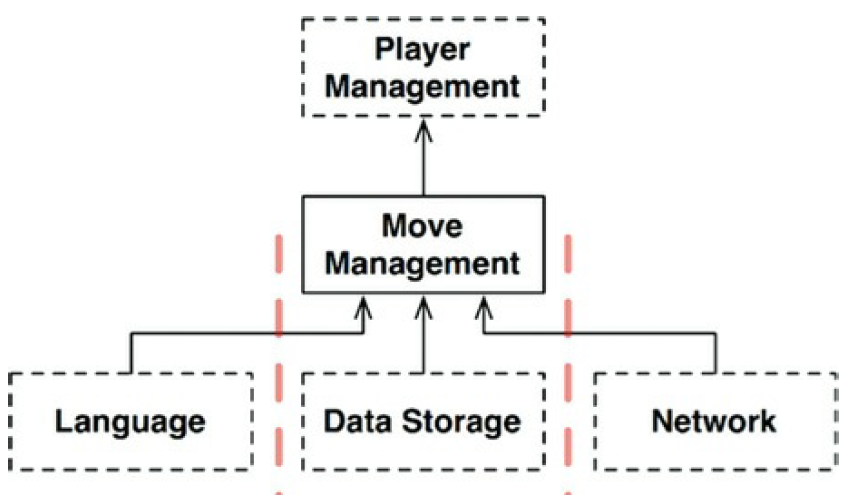
¿Es esto un límite arquitectónico? ¿Se necesita una API que separe el «MoveManagement» del
«PlayerManagement»? Bien, hagamos esto un poco más interesante y añadamos
microservicios.
Asumamos que tenemos una versión de masiva multijugador de «Hunt the Wumpus».
«MoveManagement» se trata localmente dentro de la computadora del jugador pero
«PlayerManagement» se maneja por un servidor. «PlayerManagement» ofrece un
micro-servicio API para todos los componentes «MoveManagement» conectados.
El diagrama de la siguiente figura representa este escenario de una manera algo abreviada.
Los elementos «Network» son un poco más complejos que los representados, aunque
uno se puede hacer una idea. Un límite arquitectónico completo existe entre
«MoveManagement» y «PlayerManagement» en este caso.
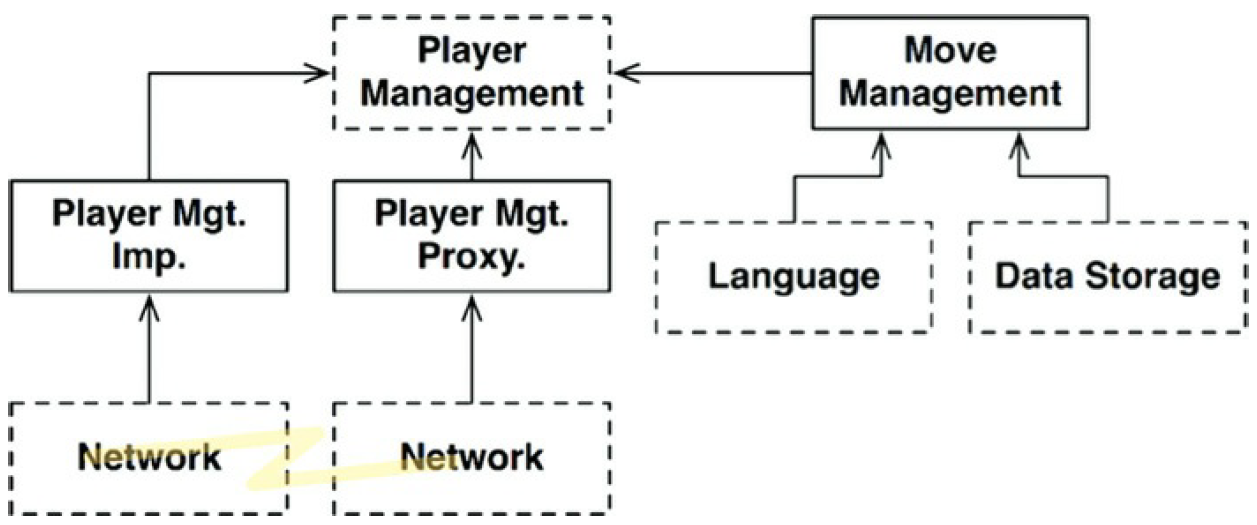
Conclusión
Este ejemplo se entiende para mostrar que los límite arquitectónicos existen en
cualquier parte. Nosotros, como arquitectos, debemos ser cuidadosos para
reconocer cuando estos son necesarios. También tenemos que ser conscientes que
cuando se implementan completamente son costosos. Al mismo tiempo, estos son
muy caros de añadirlos más tarde, incluso en presencia de conjuntos de pruebas
integrales y disciplina de refactorización.
¿Así que qué debemos hacer como arquitectos? La respuesta no es nada satisfactoria. Por
un lado, alguna gente lista dice, a través de los años, que nosotros no
deberíamos anticipar la necesidad de abstracción. Esta es la filosofía del
YAGNI: “You aren’t going to need it.” Hay sabiduría en ese mensaje, desde que
la sobre ingeniería es en ocasiones peor que la subingeniería. Por otro lado,
cuando tú descubres que tu necesitas un límites arquitectónico donde no existe,
el coste y el riesgo puede ser muy alto para añadir dicho límite.
Así que ahí está, como arquitecto software debes ver el futuro. Se debe sopesar el coste y
determinar donde los límites arquitectónicos mienten y cuáles deberían ser
implementados totalmente, cuáles deberían ser implementados parcialmente y
cuáles se deberían ignorar.
Pero esto no es un decisión única. SImplemente no se decide al principio del proyecto qué
límites implementar y cuáles ignorar. Más que eso se debe ver. Se debe poner
atención a medida que el sistema evoluciona. Se observa donde se puede
necesitar un límite y entonces cuidadosamente mirar el primer indicio de
fricción porque aquellos límites no existen.
En este punto, yo sopeso el coste de implementar aquellos límites contra el coste de
ignorarlos y esta decisión se debe revisar frecuentemente. La meta es
implementar los límites de acuerdo al punto de inflexión donde el coste de
implementar se convierte en menos que el coste de ignorar.
Se necesita un ojo vigía.
No hay comentarios:
Publicar un comentario