A lo largo de los último años han
surgido varias ideas relacionadas con la arquitectura de sistemas. Este estas
arquitecturas se incluyen:
· La arquitectura hexagonal, también conocida como puertos y
adaptadores, desarrollada por Alistair Cockburn, y adoptada por Steve Freeman y
Nat Pryce en su maravilloso libro «Growing Object Oriented Software with Tests».
· DCI de James Coplien and Trygve Reenskaug.
· BCE, presentado por Ivar Jacobson en su libro «Object Oriented
Software Engineering: A Use-Case Driven Approach».
Aunque todas estas arquitecturas varían en algunos de sus detalles ellas son muy
similares. Todas tienen el mismo objetivo, la separación de aspectos. Todos
ellos logran esta separación dividiendo el software en capas. Cada uno tiene al
menos una capa de reglas de negocio y otra capa para el usuario y los
interfaces de sistema.
Cada una de estas arquitecturas producen sistemas que tienen las siguientes características:
· Independencia del frameworks. La arquitectura no depende de la
existencia de alguna librería de cargado de software. Esto permite usar los
frameworks como herramientas más que forzar al sistema a sus limitaciones.
· Testeable. Las reglas de negocio se pueden testear sin la UI, la
base datos, el servidor o ningún otro elemento externo.
· Independencia de la UI. La UI puede cambiar fácilmente sin que
cambien las reglas de negocio.
· Independencia de la base de datos. Las reglas de negocio no están
vinculadas a una base de datos.
· Independencia de cualquier agencia externa. En realidad, las
reglas de negocio no saben nada sobre las interfaces del mundo exterior.
El siguiente diagrama es un intento de integrar todas estas arquitecturas en un
única idea.
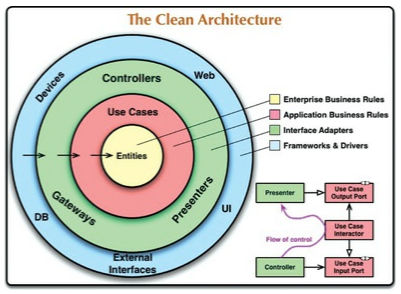
La regla de la independencia
Los círculos concéntricos representan diferentes capas de software. El círculo más interno son las políticas de alto nivel mientras que los círculos más externos son las políticas de bajo nivel o mecanismos.
La principal regla que hace posible este sistema es la «regla de la independencia».
Ningún componente de un círculo interno debe saber nada de un círculo más exterior. En
particular, el nombre de algo declarado en un círculo más exterior no se debe mencionar en un círculo más interior. Esto incluye funciones, clases, variables o cualquier otra entidad de software nombrada.
De la misma manera, los formatos de datos declarados en círculos externos no se deberían
usar en círculos más internos especialmente aquellos formatos que son
declarados por un framework en un círculo más externo. Nada de un círculo
externo debe impactar a un círculo interno.
Entidades
Las entidades encapsulan las conceptos críticos del negocio. Estas pueden ser
clases con método o estructuras de datos con funciones. Las entidades se
podrían utilizar en distintas aplicaciones.
Casos de uso
La capa de los casos de uso alberga las reglas de negocio. Un caso de uso orquesta el
flujo de datos entre entidades.
Los cambios en esta capa no deberían afectar a las entidades al igual que esta capa no
debería verse afectada por cambios en detalles como la base de datos, interfaz
de usuario, etc. La capa de uso está aislada de estos detalles.
Los cambios que afectan a las operaciones de la aplicación afectarán a los casos de uso y
se verán reflejadas en esta capa.
Adaptadores de interfaz
La capa de adaptadores de interfaz alberga un conjunto de adaptadores que convierten los
datos de entrada al formato que esperan los casos de uso y los datos de salida
del caso de uso al formato más conveniente para un agente externo como puede
ser la base de datos o la web.
Esta capa es la que contendrá la arquitectura del MVC de una GUI. Los controladores, las
vistas y modelos pertenecen a la capa de adaptadores de interfaz.
Por ejemplo, los datos que se envían desde un formulario se reciben en el
controlador y se convierten en un formato que entienda el caso de uso. Si el
caso de uso de uso requiere de un sistema de persistencia este no debería saber
nada sobre el mismo. Si el sistema de persistencia es una base de datos SQL
entonces todo el código SQL debería estar contenido en esta capa.
Frameworks y drivers
La capa más exterior alberga los detalles tales como la base de datos y el framework web.
Generalmente, no se escribe mucho código en esta capa a excepción del código
que une esta capa con la siguiente círculo interior.
¿Sólo 4 círculos?
Los círculos no son más que una directriz. Habrá casos en los que se necesiten más
capas. No obstante, estos círculos deben respetar la regla de la dependencia de
manera que todas deben apuntar al interior del círculo siempre. El círculo más
interno contiene las políticas de más alto nivel mientras que el círculo más
interno contiene las políticas de más bajo nivel o detalles.
Cruzando límites
En la siguiente imágen se puede observar de como el flujo de ejecución cruza los
límites de los círculos.
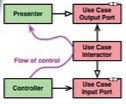
Esto muestra el controlador y al presentador comunicándose con los casos de uso
estando los casos de uso en una capa más interna. El flujo de control comienza
en el controlador, se mueve a través del caso de uso y termina ejecutándose en
el presentador. También se pueden apreciar las dependencias de código: tanto el
controlador como el presentador apuntan a los casos de uso.
Para llevar a cabo esta estrategia se utiliza el Principio de Inyección de Dependencias.
Por ejemplo, si necesitamos hacer una llamada al presentador el caso de uso no
puede hacer una llamada directa dado que esto vulneraría el Principio de
Inyección de dependencias. Así que hay que hacer una llamada a la interface
(«Use Case Input Port») en el círculo interior y tener el presenter implementado
en el círculo exterior.
Esta técnica es la misma que se usa para cruzar todos los límites en la
arquitectura. Se usa el poliformismo para crear dependencias de código fuente
que se oponen al flujo de control de manera que se puede aplicar la regla de la
dependencia sin importar la dirección del flujo de control de viaje.
¿Cómo cruzan los límites los dátos?
La forma más usual en que los datos que cruzan los límites es en forma de estructuras de
datos simples. También se pueden utilizar objetos simples o incluso simples
parámetros en la llamada a la función.
No se deben pasar ni entidades, ni filas de la base de datos, ni ningún tipo de estructura
que tenga cualquier tipo de dependencia que obligue al círculo más interno a
conocer esta. Por ejemplo, muchos frameworks de bases de datos devuelven un
formato de datos en respuesta a una consulta, un “row structure”. Si se pasara
esta estructura hacia un círculo más interno se estaría vulnerando la regla de
la dependencia ya que se está obligando al círculo interior sobre el círculo
exterior.
La regla es que, cuando se pasan datos entre límites, siempre se hace en el formato más
conveniente para el círculo interno.
Un escenario típico
El siguiente escenario muestra un típico escenario para un sistema web usando una
base de datos.
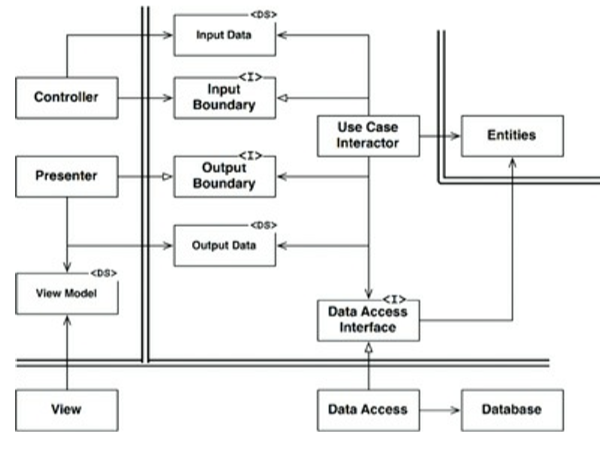
El servidor web recopila los datos de entrada del usuario y los entrega al controlador
«Controller». El controlador empaqueta esos datos en una estructura de datos y
pasa esta a través de «Input Boundary» al «Use Case Interactor». «Use Case
Interactor» interpreta estos datos y usa esto para controlar el baile de las
entidades. Este también usa el «Data Access Interface» para llevar los datos
que se han usado por las entidades, que están en memoria, a la base de
datos. Al finalizar, el «Use Case Interactor» recopila datos de las entidades y
construye la «Output Data» como otra estructura de datos. Estos datos se
comunican a través de la interfaz «Output Boundary» al presentador.
El trabajo del presentador es reempaquetar los datos de «Output Data» en forma visible
para «View Model» el cual es otra estructura de datos. El «View Model» contiene
mayormente cadenas de texto y «flags» que «View» usa para mostrar los datos.
Mientras que el «Output Data» podría contener los datos de tipo «Date», el
presentador cargará el «ViewModel» con las cadenas correspondientes formateadas
ya correctamente para el usuario. Lo mismo para cualquier otro dato como el
tipo de moneda o cualquier otro dato relativo al negocio. Los nombres «Button»
y «MenuItem» se colocan en el «View Model» así como los indicadores que le
dicen a la vista si esos elementos deberían ser grises.
Esto deja a la vista con poco más que hacer que mover los datos desde la desde el
«ViewModel» a una página HTML.
Se puede apreciar que todas las dependecias siempre cruzan los límites hacia el interior
siguiendo la regla de la dependencia.
Conclusión
Cumplir con estas normas no es muy difícil y esto ahorrará muchos dolores de cabeza en un
futuro. Separando el software en capas y conformando la regla de la dependencia
se creará un sistema que es intrínsecamente testeable con todos los beneficios
que eso implica.
Cuando cualquier parte externa del sistema queda obsoleta, ya sea la base de datos o
el framework, se pueden reemplazar estos elementos con un esfuerzo mínimo.
No hay comentarios:
Publicar un comentario