Microservicios y el problema del tratamiento de los datos distribuidos
Una aplicación monolítica suele tener todos sus datos en una única base de datos. Si es una base de datos relacional entonces la aplicación puede usar los beneficios de las transacciones ACID:
Atomicity: los cambios se hacen atómicamente.
Consistencia: el estado de la base de datos siempre es consistente.
Isolation: incluso aunque las transacciones se ejecuten concurrentemente estas aparecen como si se hubieran ejecutado en serie.
Duration: Una vez que una transacción ha finalizado esta no se deshace.
Esto permite a la aplicación hacer una transacción, cambiar múltiples filas y persistir la transacción con los beneficios anteriores.
Otro beneficio de tener una base de datos relacional es que está provee SQL con lo que se puede escribir consultas entre varias tablas mientras que el motor de SQL se encarga de todos los detalles para ejecutar la consulta liberando al programador de esta tarea.
Sin embargo, el tratamiento de los datos es mucho más complejo en la arquitectura de microservicios. Esto se debe a que cada microservicio tiene la responsabilidad de tratar sus propios datos y sólo se puede acceder a estos a través de su API. Encapsular los datos garantiza que los microservicios no estén acoplados y puedan evolucionar de manera independiente.
La dificultad se incrementa si los microservicios utilizan distintas bases de datos. Desde que cada microservicio es independiente este puede requerir de una base de datos que se adapte más a sus necesidades. Por ejemplo, un microservicio que almacena grandes cantidades de texto y hace búsquedas sobre este tendería a usar un motor de base de datos de búsqueda de texto como puede ser Elasticsearch.
El primer reto para los microservicios es mantener la consistencia entre los múltiples servicios.
Se podría usar transacciones distribuidas, también conocidas como Two-Phase Commits (2PC). Sin embargo 2PC no es viable en aplicaciones modernas debido al teorema del CAP.
El teorema del CAP, también conocido por Brewer’s theorem, establece que es imposible para un almacén de datos distribuidos proveer más de de dos de las siguientes garantías:
Consistency: cada lectura recibe la escritura más reciente o un error.
Availability: cada petición recibe una respuesta (no error) sin la garantía de que tenga la escritura más reciente.
Partition tolerance: el sistema continúa funcionando incluso si un número arbitrario de mensajes se han descartado o se retrasan entre nodos de la red.
El segundo reto es cómo implementar las consultas que obtienen datos de múltiples servicios dado que cada microservicio tiene sus propios datos.
Arquitectura dirigida por eventos o «Event-Driven Architecture»
La solución pasa por usar una arquitectura dirigida por eventos o «Event-Driven Architecture». En esta arquitectura, un microservicio publica un evento cuando algo notable ocurre. Por ejemplo, la creación de una nueva entidad. Otros microservicios pueden estar suscritos a estos eventos y pueden reaccionar ante tales eventos ya sea creando una nueva entidad, modificando una existente, borrando, etc. lanzando a su vez sus propios eventos.
Es importante advertir que estas no son transacciones ACID lo cuál ofrece garantías mucho más débiles que la consistencia eventual.
Una desventaja es que, como no son transacciones ACID, entonces hay que implementar el sistema de manera que se pueda recuperar de los fallos por negocio.
Imagina que para que un cliente pueda realizar un pedido deba disponer del crédito suficiente. En este caso, el cliente realizará el pedido de manera que el microservicio de pedidos recibirá, a través de su api, un petición para dar de alta un pedido. Este guardará el pedido a través de un mecanismo de persistencia, como puedes una base de datos relaciona MariaDb, para posteriormente enviar un evento de tipo «pedido creado» a un software de negociación de mensajes o broker de mensajería como pueden ser RabbitMQ o Apache Kafka.
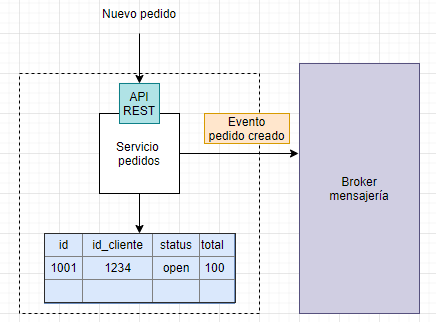
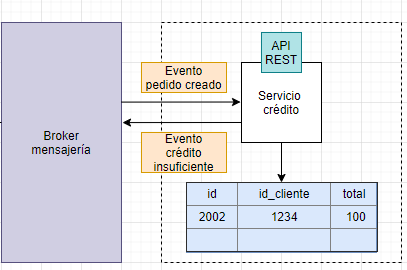
A su vez, el microservicio de créditos, estará escuchando este tipo de eventos («pedido creado»). Este procesará el evento de manera que compruebe si el cliente tiene el crédito necesario. En el caso de no tener el crédito necesario lanzará un evento «crédito insuficiente»
El servicio de pedidos estará escuchando este tipo de eventos. Procesará el evento y actualizará el pedido con un estado de crédito insuficiente.
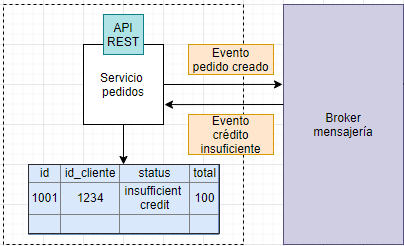
Como se puede apreciar, tanto la arquitectura software como hardware es más compleja que utilizando una única base de datos con las transacciones ACID ya que hay que tener cubrir los fallos de negocio, como por ejemplo que no haya crédito suficiente.
Otros retos a los que se enfrentan los desarrolladores son la inconsistencia de los datos debido a que ya no hay transacciones ACID y que los suscriptores de eventos deben detectar e ignorar los eventos duplicados.
Atomicidad
En la arquitectura dirigida por eventos o «Event-Driven Architecture» hay un problema de atomicidad en cuanto a actualizar la base de datos y publicar el evento.
Por ejemplo, el microservicio de pedidos debe registrar el nuevo pedido en su base de datos y publicar el evento «Pedido creado». Es esencial que este par de operaciones se hagan atómicamente. Si por alguna razón la ejecución del servicio se interrumpe después de actualizar la base de datos, entonces el sistema quedará en un estado inconsistente.
La manera estándar de asegurar la atomicidad sería usar una transacción distribuida involucrando a la base de datos y el «broker de mensajería». Sin embargo, por el teorema del CAP, eso es lo que no queremos hacer.
Para solventar el problema se pueden utilizar 3 estrategias:
Usar la base de datos como una cola de mensajes.
Minado de del log de transacciones.
“event sourcing”.
Estas estrategias pasan a desarrollarse a continuación
Publicando eventos usando transacciones locales
Una estrategia para lograr la atomicidad es utilizar un proceso en varios pasos utilizando transacciones locales. El truco es tener una tabla «EVENTS» de manera que la aplicación actualice la entidad, inserte un evento en registro en la tabla «EVENTS» y haga commit de la transacción. Por otro lado, otro proceso, un administrador de eventos, se encarga de publicar estos eventos en el «broker de mensajería» y actualizarlos como publicados
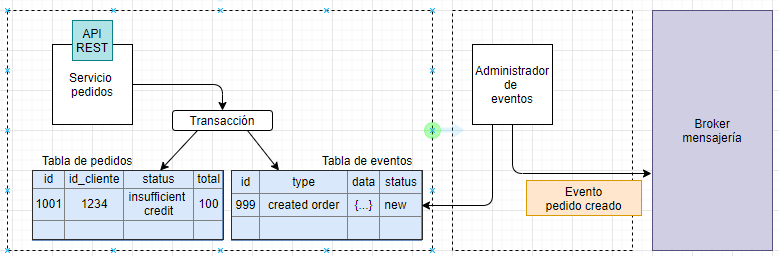
La ventaja es que garantiza que el evento se publique sin recurrir al «two phase commit» o 2pc.
Una desventaja es que responsabiliza al programador de añadir los eventos, con lo que en algún momento puede olvidarse. Otra posible inconveniente podría ser el uso de algunas bases de datos NoSql que no tengan las capacidades de transacciones.
Minando el log de transacciones de la base de datos
Otra manera de lograr la atomicidad «two phase commit» o 2pc es tener otro proceso que examine el log de transacciones o commits. Cuando este proceso encuentra una transacción entonces publica un evento.
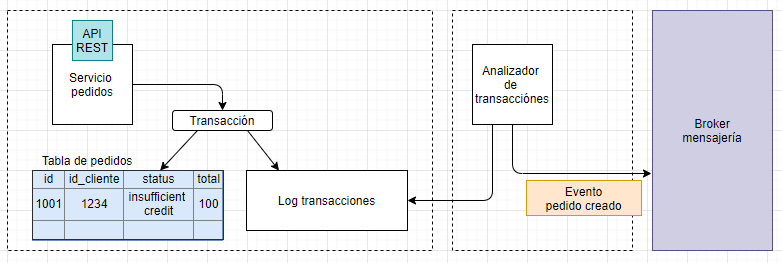
Con esta estrategia se garantiza que se publica un evento por cada transacción a la vez que simplifica la aplicación separando esta de la publicación de eventos.
Una desventaja es que cada base de datos tiene su propio formato de log de transacciones y que, para que sea un reto más interesante, este puede cambiar entre versiones. También puede ser difícil hacer ingeniería inversa de los eventos de alto nivel de las actualizaciones.
Usar Event Sourcing
La arquitectura «Event Sourcing» logra la atomicidad sin el «Two Phase Commit» (2PC) con un enfoque distinto para persistir las entidades de negocio. Más que guardar el estado de la entidad, lo que guarda la aplicación es la secuencia de eventos de cambio. De manera que la aplicación puede reconstruir el estado actual de una entidad recorriendo todos los eventos. Cuando el estado de una entidad cambia, se añade un nuevo evento y esta operación ya es atómica de por sí.
Los eventos persisten en un almacén de eventos o «Event Store». Este almacén tiene una API para añadir y recibir eventos de una entidad. Este también se comporta como el «Broker de mensajería» el cual entrega los eventos a los suscriptores.
Si continuamos con el ejemplo del a creación del pedido, el microservicio de pedidos haría una petición a la API del «Event Store» para crear el evento de «pedido creado». Este registraría el evento y enviaría un evento «pedido creado» al microservicio de crédito. Este procesaría el evento y haría una petición para registrar el evento «crédito insuficiente». El «Event store» procesaría la petición registrando el evento y enviaría este al microservicio de pedidos.

Los principales beneficios de esta arquitectura es que solventa los problemas de la consistencia de datos a la par que provee un log de los cambios de una entidad de negocio. Otro beneficio es que la lógica de negocio consiste en entidades de negocio pobremente acopladas que intercambian eventos.
Como desventajas tiene que es un estilo de programación un tanto diferente y, por ende, tiene una curva de aprendizaje. El almacén de eventos sólo admite la búsqueda de entidades de negocio por clave primaria. Se debe usa la «Separación de comandos y consultas», o por sus siglas en inglés, el «Command Query Responsibility Separation» (CQRS) para implementar las consultas.
Resumen
En la arquitectura de microservicios cada microservicio almacena sus datos en su propia base de datos, ya sea Sql y NoSql. Esta distribución de los datos conlleva nuevos retos que afrontar como mantener la consistencia entre los múltiples microservicios o recuperar los datos desde múltiples microservicios.
Para muchas aplicaciones la solución pasa por usar una arquitectura dirigida por eventos. El reto de esta arquitectura es actualizar el estado de forma atómica y cómo publicar eventos. Para acometer tal reto hay varias estrategias como usar la base de datos como cola de mensajes, minar el log de transacciones y el almacén de eventos o «Event Sourcing».
No hay comentarios:
Publicar un comentario