Cruce de límites
En tiempo de ejecución
un cruce de límite no es más que una función en una cara del límite llamando a
una función del otro lado pasándole unos datos. El truco para crear un
apropiado cruce de límites es administrar las dependencias del código
fuente.
¿Por qué el código
fuente? Porque cuando un módulo de código fuente cambia otro módulos pueden
tener que cambiar o recompilar y, entonces, redesplegar. Administrar y
construir esos cortafuegos contra esos cambios es el propósito de los límites.
El temido monolito
Es el más simple y común
de los límites arquitectónicos ya que no tiene una representación física
estricta. El monolito es una organización de funciones y datos dentro de un
mismo servidor.
El hecho de que el
monolito no tenga unos límites físicos no quiere decir que no estén presentes y
no tengan significado. La habilidad para desarrollar independientemente los
diversos componentes para el ensamblaje final tiene un valor enorme.
El cruce de límite más
simple es una llamada desde un cliente de bajo nivel a un servicio de alto
nivel.
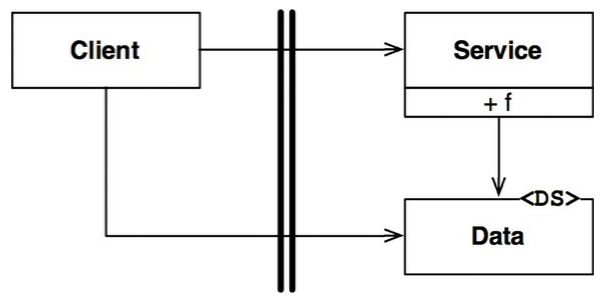
En la siguiente figura
se puede observar como el flujo de control cruza el límite de izquierda a
derecha. El cliente «client» llama a la función «f()» de «Service». Este pasa
una una instancia de «Data». El marcador «DS» indica una estructura de datos. Los
datos «Data» se pueden pasar como un argumento a la función «f()» o por otro
medio un poco más elaborado. Se puede observar que la definición de «Data» se
encuentra en el lado del servicio.
Cuando un cliente de
alto nivel necesita invocar un servicio de bajo nivel, el polimorfismo dinámico
se utiliza para invertir la dependencia contra el flujo de control. La
dependencia en tiempo de ejecución se opone a la dependencia en tiempo de
compilación.
En la siguiente figura
se puede observar que se cruzan los límites de izquierda a derecha, igual que
antes. El cliente de alto nivel hace una llamada a la función «f()» de el
servicio de bajo de nivel «service impl» a traves de la interfaz «Service».
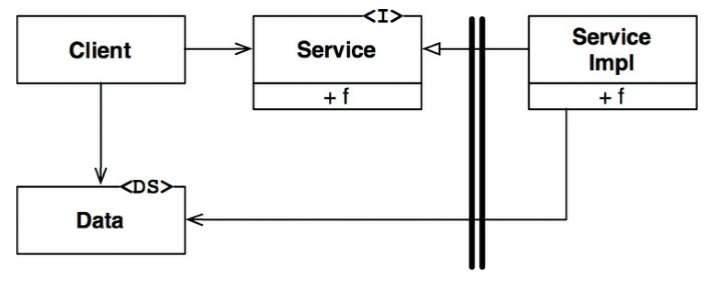
En este caso se puede
apreciar como todas las dependencias cruzan los límites de la derecha a la
izquierda hacia el componente de nivel superior. Nótese también que la
definición de la estructura de datos está en el lado izquierdo del
límite.
Incluso en un monolito,
este tipo de particionado disciplinado puede ser de gran ayuda para el
desarrollo, pruebas y despliegue. Los equipos pueden trabajar
independientementes unos de otros en sus propios componentes sin pisarse entre
ellos.
Los componentes de alto
nivel permanecen independientes de los niveles de bajo nivel.
Despliegue de
componentes
El despliegue es
simplemente el encuentro de los distintos componentes de alguna forma que se
pueden ejecutar.
Threads
Tanto los monolitos como
sistemas más sofisticados pueden usar «threads». Estos no son límites
arquitectonicos o unidades de despliegue pero son una manera de organizar la
programación y el orden de ejecución. Pueden estar totalmente contenidos dentro
de un componente o extenderse a través de muchos componentes.
Procesos locales
De lejos el límite
arquitectonico más fuerte es el proceso local. Un proceso local se crea
típicamente desde la consola o una llamada local equivalente. Los procesos
locales se suelen comunicar por sockets o algún otro tipo de sistema de
comunicación como colas de mensajería o mailboxes.
Un proceso local es como
una especie de súper componente: el proceso consiste en componentes de nivel
inferior que gestionan sus dependencias a través del polimorfismo dinámico.
La estrategia de
segregación entre procesos locales es la misma que para los monolitos y
componentes binarios. Las dependencias del código fuente apuntan en la misma
dirección a través del límite, y siempre hacia el componente de nivel superior.
Para los procesos
locales, esto significa que el código fuente de los procesos de nivel superior
no debe contener los nombres, las direcciones físicas o las claves de búsqueda
del registro de los procesos de nivel inferior. Recuerde que el objetivo
arquitectónico es que los procesos de nivel inferior sean complementos de
procesos de nivel superior.
La comunicación a través
de los límites del proceso local implica llamadas al sistema operativo, cálculo
y descodificación de datos e interruptores de contexto entre procesos, que son
moderadamente costosos. El chattiness debe ser cuidadosamente limitado.
Servicios
El límite más marcado es
un servicio. Un servicio es un proceso, generalmente empezado desde la línea de
comandos o a través de una llamada al sistema equivalente. Los servicios no
dependen de su localización física. Dos servicios pueden o no operar en el
mismo procesador o núcleo múltiple. Los servicios asumen que toda la
comunicación toman lugar a través de la red.
La comunicación entre
los límites de los servicios son muy lentas en comparación con las llamadas a
funciones. Los tiempos de respuesta pueden variar de decenas de milisegundos a
segundos. Se debe evitar chatear cuando sea posible dado que la comunicación a
este nivel implica altos niveles de latencia.
De otra manera, las
mismas reglas aplican a servicios como a procesos locales. Los servicios de
bajo nivel deberían enchufar a los servicios de alto nivel. El código fuente de
los servicios de alto nivel no deben contener ningún conocimiento físico (por
ejemplo una URL) de ningún servicio de bajo nivel.
No hay comentarios:
Publicar un comentario