En las aplicaciones monolíticas la comunicación entre los distintos módulos se hace mediante llamadas a funciones del lenguaje. Por regla general, todo se ejecuta en el mismo proceso. Sin embargo, en las aplicaciones basadas en microservicios los módulos se ejecutan ya no en procesos distintos si no en distintas máquinas.
Para que los microservicios se puedan comunicar hay que definir qué tipo de comunicación va a utilizar un microservicio determinado.
La comunicación de los servicios puedes ser:
Y esta comunicación se puede producir de forma:
Los IPC se pueden categorizar en los siguientes:
| One to one | One to many |
Sincrono | Request/response | - |
Asíncrono | Notification
| Publish/subscribe |
Request/async response | Publish/Async response |
Como se puede apreciar, las peticiones “One to one” se dividen en:
Request/Response: un cliente hace la petición y espera la respuesta.
Notification: el cliente envía una petición al servicio pero no espera una respuesta del mismo.
Request/Async response: un cliente envía una petición al servicio el cual responde asíncronamente.
Las peticiones “one to many” se dividen en:
Publish/subscribe: un cliente publica un mensaje de notificación en una cola en la cual pueden estar escuchando de cero a n consumidores.
Publish/async responses: Un cliente publica un mensaje de solicitud y entonces espera cierta cantidad de tiempo por las respuestas de aquellos servicios que están interesados.
Los servicios puedes utilizar uno varios de estos de mecanismos de comunicación.
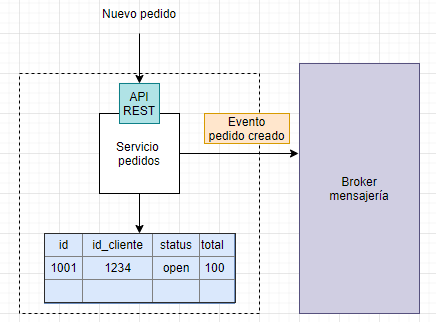
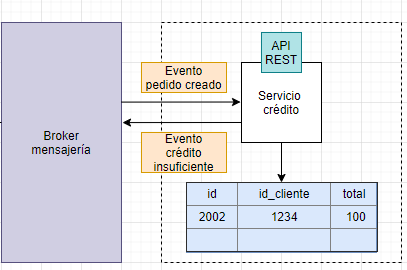
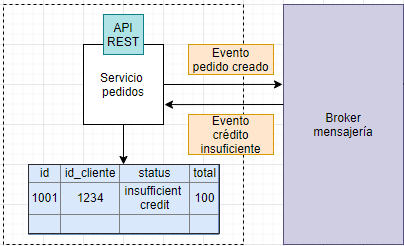
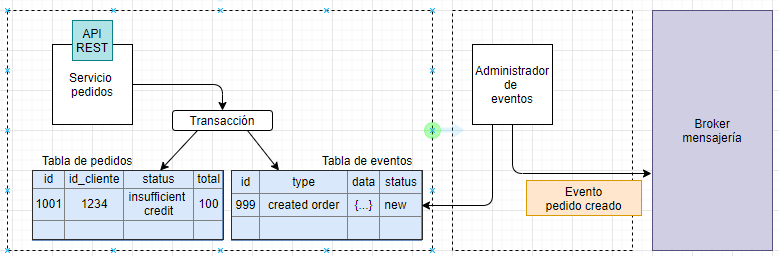
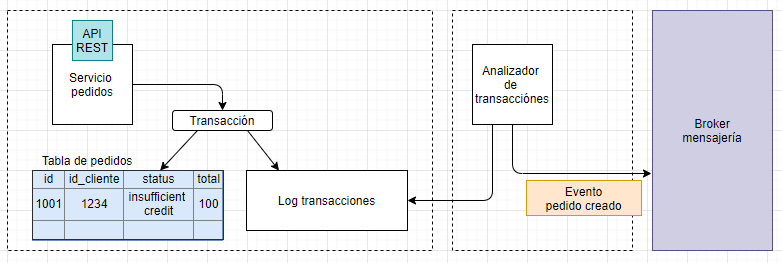
En el siguiente ejemplo se puede ver una posible solución a la solicitud de un viaje para una empresa tipo Uber.

El pasajero solicita un viaje desde su aplicación al «administrador de viajes». Este consulta los datos necesarios al «administrador de pasajeros» mediante una llamada REST y, si el usuario puede solicitar viajes, entonces manda una notificación al administrador de notificaciones para alertar a los posibles conductores. Las aplicaciones de los conductores están escuchando en una cola de mensajes las solicitudes de viajes.
Definiendo APIs
Una API es una interfaz que define el intercambio de información con un componente a través de un límite establecido. Esta debería definir el tipo de comunicación, las respuestas, los formatos de datos, etc.
Para definir una API es fundamental utilizar algún tipo de «Interface Definition Language» (IDL). Este vendrá definido por el tipo de mecanismo (IPC) que se use. Por ejemplo, si es HTTP la API consiste en URL y los formatos de petición y respuesta, si se usa message en la API dependerá de los tipo de canal y mensajes.
Envolviendo APIs
Las API tienden a ir evolucionando con el tiempo esto conlleva a determinados cambios como nueva funcionalidad, cambios en la misma o incluso eliminar funcionalidades obsoletas. Estos cambios tienen un impacto directo en los clientes que utilizan esa API.
En el caso de un monolito los cambios son más directos y se cambian aquellas llamadas que hacen uso de la API. En el caso de los microservicios no es tan sencillo ya que no se puede formar a los clientes a actualizar sus servicios.
Si los cambios son cambios menores los cuales son retrocompatibles como por ejemplo añadir atributos, lo clientes que usaban la API vieja podrán utilizar la nueva versión si el servicio establece valores por defecto.
En el caso de cambios mayores que no sean retrocompatibles no se puede forzar a los clientes a actualizar a la nueva versión por lo que el servicio debe poder soportar las versiones más antiguas por un periodo de tiempo.
Una estrategia para abordar este problema sería desplegar nuevas versiones del servicio de manera que se ejecuten simultáneamente. Por ejemplo, si se está usando un mecanismo HTTP como REST una estrategia comúnmente utilizada es añadir un número de versión en la URL. Cada servicio podría servir múltiples versiones simultáneamente.
Tratando con los fallos parciales
En cualquier sistema distribuido siempre está presente el riesgo de fallo. Cualquier de los servicios podría estar caído o no responder en un tiempo adecuado por esta razón es fundamental diseñar el sistema para tratar con estos fallos parciales.
Entre las estrategias para tratar con los fallos parciales se incluyen:
Networks timeouts: cuando se espera una respuesta de un servicio esta debe tener un tiempo límite establecido de manera que no se quede bloqueada indefinidamente.
Limitar el número de solicitudes pendientes: se debería establecer un límite de solicitudes pendientes de manera que cuando se alcance ese límite las peticiones entrantes existe una alta probabilidad de que el servicio se degrade y no pueda hacerse cargo de las peticiones por lo que estas deberían fallar inmediatamente.
Circuit breaker pattern: si se monitorizan las peticiones se puede conocer el porcentaje que estás que están fallando. Se puede establecer un límite de peticiones fallidas de manera que cuando este límite se supere se rompa el circuito y provoque que el resto de las llamadas fallen inmediatamente. El componente «circuit breaker» monitorizará el servicio de manera que cuando vuelva a estar operativo permita las llamadas al mismo.
Establecer fallbacks: si una petición falla se debería proporcionar qué hacer. Por ejemplo, si el servicio de comentarios no está disponible se podría utilizar datos guardados o valores por defecto.
IPC síncrona
Los mecanismos IPC syncronos basados en petición y respuesta consisten en que un cliente hace una petición a un servicio, este procesa la petición y envía la respuesta al cliente. En estos casos los clientes se quedan a la espera de la respuesta.
Los dos protocolos más populares para este tipo de comunicación son REST y Thrift.
REST
REST es un mecanismo IPC que utiliza el protocolo HTTP.
Existen dos conceptos clave:
REST establece que los recursos y colecciones tienen una URL la cual define cada uno de estos. Para manipular las colecciones y recursos se realizan peticiones utilizando los verbos del protocolo HTTP. Por ejemplo, las peticiones de tipo GET obtendran un recurso o colección, las peticiones de tipo POST crearán un nuevo recurso mientras que las de tipo PUT actualizarán un recurso.
Roy Fielding es el creador de REST y establece la arquitectura en:
Un ejemplo de REST podría ser la aplicación móvil de un pasajero creando un nuevo viaje en el administrador de viajes.

La aplicación hace una petición de tipo POST a la url «/trips» de la API REST del administrador de viajes. El servicio trata la petición verificando los datos enviados en la petición para, en el caso de crear el viaje, devolver una respuesta con el código HTTP 201 (recurso creado).
Cómo se dijo antes, REST es un mecanismo IPC que se basa en el protocolo HTTP y, por lo tanto, puede hacer uso de este protocolo de distintas maneras.
Leonard Richardson define un modelo de madurez para REST con 4 niveles.
Nivel 0
La API tiene un sólo punto final de comunicación el cual recibe las peticiones de tipo POST de los clientes. Cada petición especifica qué acción se quiere realizar, sobre qué recursos y los datos necesarios para llevar a cabo la acción.
Nivel 1
Este nivel incluyen la idea de recursos. Ya no existe un único punto final de comunicación si no que cada recurso tiene su propio punto final. Los clientes harán una petición de tipo POST que especifica la acción a realizar y los datos necesarios para llevar a la acción.
Nivel 2
Al nivel anterior se le añade el uso de los verbos HTTP para indicar la acción que se quiere realizar sobre el recurso o la colección. Por ejemplo, una petición tipo POST creará un recurso mientras que una petición de tipo GET obtendrá un recurso ya creado.
Nivel 3
En este nivel, la representación de un recurso obtenido por una llamada de tipo GET contiene las acciones que se pueden realizar sobre ese recurso y los puntos finales donde realizar cada acción.
Este diseño se basa en el principio Hypertext As The Engine Of Application State o, por sus siglas, HATEOAS. Una de las principales ventajas de este principio es que los clientes no están acoplados a los puntos finales de cada recurso. Otra ventaja es que, al venir qué acciones se pueden realizar sobre ese recurso los clientes se evitan peticiones a acciones que no están disponibles en esos momentos.
Hay muchos beneficios de usar un protocolo que esté basado en HTTP:
HTTP es simple y familiar.
Hay una gran cantidad de herramientas para probar las API.
Soporta la comunicación petición/respuesta.
Es amigable con los cortafuegos.
No requiere de un intermediario por lo que simplifica la arquitectura del sistema.
Los inconvenientes de usar un protocolo HTTP:
Sólo soporta la comunicación petición/respuesta.
Tanto el cliente y el servicio deben estar ejecutándose durante el intercambio de comunicación.
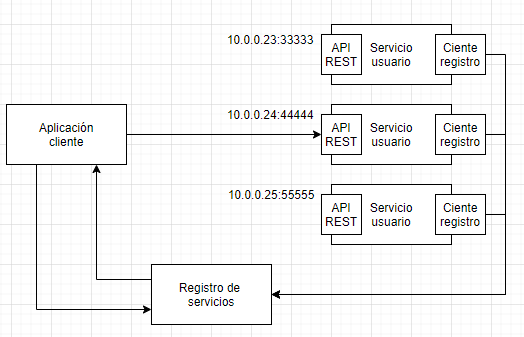
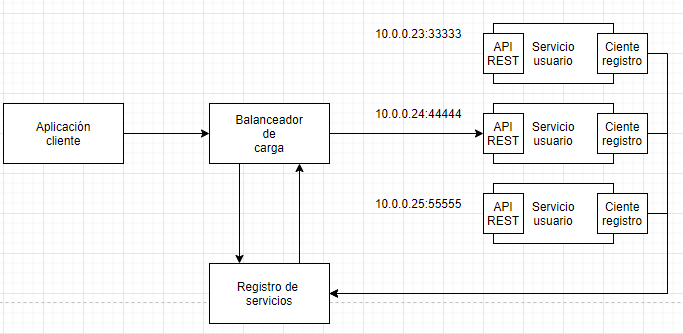
El cliente debe conocer la localización de cada instancia de servicio. Como se describió en la parte del API Gateway esto no es un problema trivial.
Thrift
Apache thrift es una alternativa a REST. Es un framework para escribir llamadas a procedimientos remotos o RPC entre clientes y servidores. Este provee un IDL del estilo de C para definir las API.
Formatos de los mensajes
Es importante que el formato de los lenguajes sea independiente de un lenguaje en concreto incluso si se está utilizando un mismo lenguaje para implementar los distintos microservicios. Nunca se sabe si en un futuro se utilizará otro lenguaje.
Hay dos tipos de mensajes: binarios y de texto.
Hay varios formatos de mensajes binarios. Si se utiliza Thrift RPC se puede utilizar el formato Thrift binary. Otras opciones populares son Procotol Buffers y Apache Avro.
En cuanto a los mensajes de texto hay dos formatos muy populares: XML y JSON. Estos formatos no sólo tienen la ventaja de que se pueden leer directamente si no que son auto descriptivos. Por ejemplo, en formato JSON los atributos de un objetos se representan mediante una colección de pares nombre-valor. En XML los elementos se representan por elementos y valores.
La principal desventaja de estos formatos de texto es que tienden a ser verbosos, en especial el XML lo que puede resultar en una perdida de rendimiento al tener que analizar estos.
Resumen
Los servicios se tienen que comunicar a través de un mecanismo de comunicación entre procesos. Cuando se describe cómo se van a comunicar los servicios se tiene que especificar la API para cada servicio, ćomo interactuan los servicios, cómo envolver esas API, cómo tratar con los fallos parciales. Hay dos tipos de mecanismos que los servicios pueden utilizar: mensajes asíncronos o peticiones y respuestas síncronas.