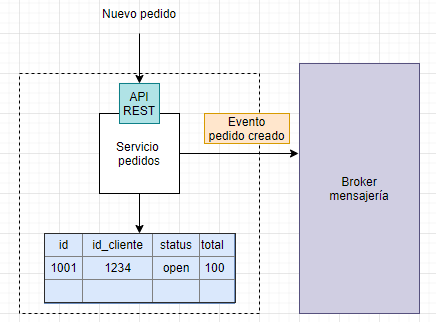
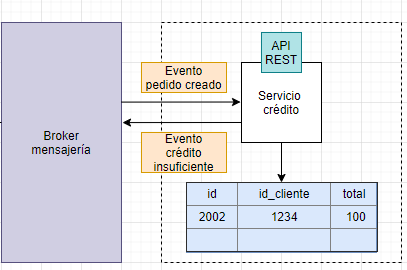
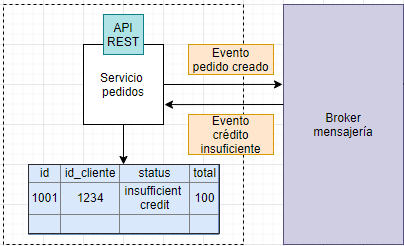
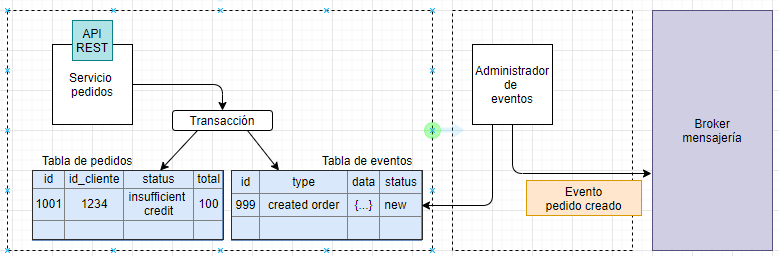
Resumen
general de refactorizar los microservicios
El
proceso de transformar un monolito a microservicios es una forma de
refactorizar la aplicación. Esto es algo que los desarrolladores han
estado haciendo durante décadas por lo que se pueden reutilizar
algunas ideas.
La
estrategia del Big Bang. Esta estrategia consiste en desarrollar la
aplicación con microservicios desde 0. Una estrategia que NO se usa
dado que hay una alta probabilidad de que termine en fallo. Martin
Fowler
dijo
“La única cosa que garantiza una estrategia de Big Bang es un Big
Bang!”.
Otra
estrategia más conservadora es refactorizar de forma incremental el
monolito. Esto significa que las nuevas funcionalidades podrían
desarrollarse en microservicios así como algunas de las
funcionalidades ya existentes. Con el paso del tiempo, la cantidad de
funcionalidad que alberga el monolito va disminuyendo hasta que este
desaparece o se convierte en otro microservicio.
Martin
Fowler se refiere a esto como «Strangler
Application».
El nombre viene por la vid estranguladora de los bosques lluviosos,
la cual crece alrededor de un árbol. En ocasiones, el árbol muere
mientras que la vid continúa viva. Esta estrategia de
refactorización sigue el mismo patrón.
Esta
estrategia se puede abordar de distintas maneras.
Estrategia
1: Para de cavar
La
ley de los hoyos o «the
Law of holes»
establece, por inverosimil que parezca, que siempre que estés en un
hoyo se debería parar de cavar para que salir no sea aún más
difícil. Esto significa que hay que dejar de hacer el monolito más
grande. La idea para esta estrategia es crear un microservicio donde
poner ese nuevo código.

Esta
estrategia requiere de un router el cual redirige la petición al
microservicio en caso de ser necesario.Es similar al gateway.
El
otro componente que se requiere es el código pegamento que integra
el servicio con el monolito. Es poco frecuente que un servicio esté
aislado y lo normal es que necesite acceso a datos que tenga el
monolito. El código pegamento tiene la responsabilidad de la
integración de los datos entre el servicio y el monolito.
Para
la integración de los datos se pueden utilizar 3 estrategias:
Invocar
una API proporcionada por el monolito.
Acceder
directamente a la base de datos de monolito.
Mantener
su propia copia de los datos, la cual está sincronizada con los
datos del monolito.
A
este código pegamento a veces se le denomina “capa
anticorrupción”. Esto es porque el código pegamento previene al
servicio, el cual tiene sus propios conceptos de dominio, de que se
contamine con los conceptos de dominio del monolito. El código
pegamento hace la traducción entre los dos dominios. El término
“capa anticorrupción” aparece por primera vez en el libro
«Domain
Driven Design»
de Eric
Evans.
El desarrollo de una capa anticorrupción puede no ser algo trivial
pero es algo que hay que hacer si se quiere dejar de el monolito.
Esta
estrategia no ataja el problema del monolito en sí ya que se
necesita romper el monolito.
Estrategia
2: Dividir el frontend y el backend
Una
estrategia que reduce el monolito es dividir la capa de presentación
de la capa de lógica de negocio y las capas de acceso a datos. Una
típica aplicación está compuesta por al menos tres componentes:
Capa
de presentación:
es la interfaz de usuario. Podría ser una página HTML o una API.
Capa
de lógica de negocio:
alberga las reglas de negocio.
Capa
de acceso a datos:
componentes que acceden a componentes de la infraestructura como
puede ser una base de datos o una cola de mensajes.
Como
se puede apreciar en la siguiente imagen, la estrategia consiste en
crear una API con toda la lógica de negocio.

Dividir
el monolito de esta manera tiene dos ventajas:
No
obstante, esto es una solución parcial dado que hay una alta
probabilidad de que uno o ambas aplicaciones se conviertan en
monolitos. Se necesita de una tercera estrategia para eliminar los
monolitos restantes.
Estrategia
3: extraer servicios
Esta
estrategia consiste en convertir los módulos del monolito en
microservicios. Cada vez que se extrae un módulo a un microservicio,
este mengua. Una vez que se hayan extraído suficientes módulos el
monolito dejará de ser un problema.
Priorizando
qué módulos convertir a servicios
La
cantidad de módulos que puede albergar un buen monolito puede ser de
decenas y cientos todos los cuales pueden ser candidatos para la
extracción. Así que una buena estrategia es extraer un módulo que
sea fácil de extraer. Esto va a proporcionar la experiencia
necesaria para las siguientes extracciones.
La
prioridad de los módulos dependerá del beneficio que se obtenga y
el principal beneficio de un microservicio es que se pueda
desarrollar y desplegar independientemente por lo que los módulos
que tienda a un mayor cambio deberían tener más prioridad.
También
son buenos candidatos aquellos módulos que tienen unos requisitos de
recursos significativamente diferentes. Por ejemplo, un módulo que
requiera una cantidad de memoria y/o procesamiento significativos. La
extracción de estos módulos a microservicios proporcionan la
oportunidad de desplegarlos en las máquinas con los requisitos
adecuados haciendo la aplicación más sencilla y escalable.
También
es útil buscar aquellos módulos que sean de grano grueso, por
ejemplo, aquellos que se comunican con el resto por mensajes
asíncronos. La conversión de estos módulos a microservicios puede
ser relativamente fácil.
Cómo
extraer un módulo
El
primer paso es definir una interfaz entre el módulo y el monolito.
Habrá mucha probabilidad en que sea una API bidireccional ya que el
monolito necesitará de los datos del servicio y viceversa.
La
implementación puede llegar a ser un reto dependiendo de como
lleguen a estar las dependencias entre el módulo y el resto de las
aplicaciones.
En
el siguiente ejemplo se ha extraído el módulo Z del monolito.

Para
poder hacer la extracción se tienen que definir las interfaces.
Estas interfaces usarán un mecanismo inter process communication
(IPC) .
El
módulo Z es el candidato a extraer. Este módulo utiliza el módulo
Y mientras que el módulo X utiliza a Z. Entonces, el primer paso es
definir un par de API. La primera interfaz es una interfaz para
invocar al módulo Z. La segunda interfaz es para que el módulo Z
pueda invocar al módulo Y.

El
segundo paso es crear un servicio independiente para el módulo Z.
Las interfaces de entrada y salida están implementadas por el código
que usa un mecanismo IPC. Lo más probable es que se requiera de un
framework de microservicios que maneje los aspectos más
transversales como el «service discovery» liberando al
desarrollador de tal tarea.

Una
vez se ha extraído el módulo del monolito este se puede
desarrollar, desplegar y escalar independientemente tanto del
monolito como de otros microservicios. Incluso se podría reescribir
el servicio desde 0. El código API que integra el servicio con el
monolito se convierte en una capa anticorrupción que traduce entre
los dos modelos de dominio.
Resumen
Nunca
se debería migrar el proyecto a microservicios reescribiendo la
aplicación completamente. En vez de eso se debería refactorizar
partes de la aplicación en iteraciones.
Las
tres estrategias que se pueden usar son:
Implementar
una nueva funcionalidad en microservicios.
Separar
la capa de presentación de la lógica de negocio.
Convertir
módulos del monolito en microservicios.
Con
el tiempo el número de microservicios crecerá con lo que la
agilidad y la velocidad del equipo de desarrollo se verá
incrementada.